Data ingestion
Data ingestion consists of 3 steps:
- Transforming metadata (including phenotypic data).
- Transforming genomic variations (VCF).
- Load data into MongoDB.
Important
Here we will give you an overview of the tree steps. For an in depth explanation, please follow this tutorial.
1. Transforming Metadata (Including Phenotypic Data)
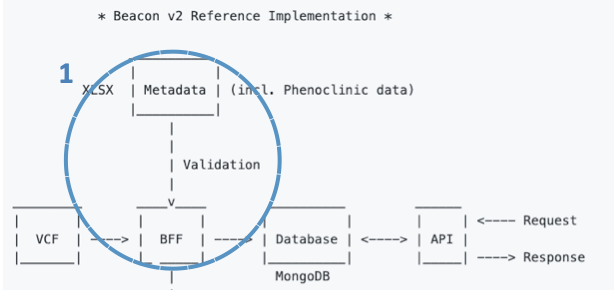
B2RI facilitates transforming your data—such as sequencing methodologies, bioinformatics tools, and phenotypic data—into the format defined by the Beacon v2 Models, using the bff-validator utility.
The Beacon v2 Models establish the default data structure (schema) for biological data responses. These models are defined using JSON Schema and organized hierarchically. The schemas consist of multiple properties or terms (also known as objects).
We have chosen MongoDB as a de facto database because it natively supports JSON documents. This allows us to store data directly in the database according to the Beacon v2 Models and provide Beacon v2 compliant responses without needing to re-map the data at the API level.
2. Transforming Genomic Variations (VCF)
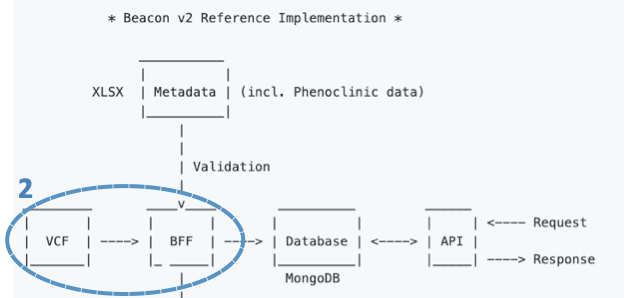
For genomic data, B2RI provides a tool (beacon) that takes a VCF file as input and uses BCFtools, SnpEff, and SnpSift to annotate the data. Once annotated, the tool transforms the VCF data into the genomicVariations entry type defined by the Beacon v2 Models and serializes it into a JSON file.
3. Loading Data into MongoDB
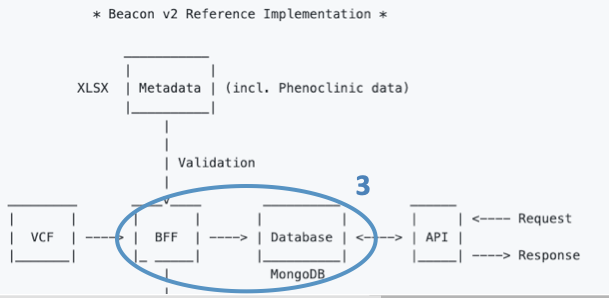
After transformation, the JSON files adhere to what we call the Beacon Friendly Format (BFF).
The final step is loading the BFF files into a MongoDB instance. B2RI provides a tool (beacon) that loads BFF files into MongoDB. Once loaded, these files are referred to as collections.
Included Utilities
In addition to the beacon script and bff-validator, the data ingestion tools include several utilities to assist with data processing and beyond:
Furthermore, the beacon2-ri-tools repository includes the CINECA synthetic dataset.